Dynamic Schema
When tables are created without any schema, through the operations API (without specifying attributes) or studio, the tables follow "dynamic-schema" behavior. Generally it is best-practice to define schemas for your tables to ensure predictable, consistent structures with data integrity and precise control over indexing, without dependency on data itself. However, it can often be simpler and quicker to simply create a table and let the data auto-generate the schema dynamically with everything being auto-indexed for broad querying.
With dynamic schemas individual attributes are reflexively created as data is ingested, meaning the table will adapt to the structure of data ingested. HarperDB tracks the metadata around schemas, tables, and attributes allowing for describe table, describe schema, and describe all operations.
Databases
HarperDB databases hold a collection of tables together in a single file that are transactionally connected. This means that operations across tables within a database can be performed in a single atomic transaction. By default tables are added to the default database called "data", but other databases can be created and specified for tables.
Tables
HarperDB tables group records together with a common data pattern. To create a table users must provide a table name and a primary key.
- Table Name: Used to identify the table.
- Primary Key: This is a required attribute that serves as the unique identifier for a record and is also known as the
hash_attributein HarperDB operations API.
Primary Key
The primary key (also referred to as the hash_attribute) is used to uniquely identify records. Uniqueness is enforced on the primary; inserts with the same primary key will be rejected. If a primary key is not provided on insert, a GUID will be automatically generated and returned to the user. The HarperDB Storage Algorithm utilizes this value for indexing.
Standard Attributes
With tables that are using dynamic schemas, additional attributes are reflexively added via insert and update operations (in both SQL and NoSQL) when new attributes are included in the data structure provided to HarperDB. As a result, schemas are additive, meaning new attributes are created in the underlying storage algorithm as additional data structures are provided. HarperDB offers create_attribute and drop_attribute operations for users who prefer to manually define their data model independent of data ingestion. When new attributes are added to tables with existing data the value of that new attribute will be assumed null for all existing records.
Audit Attributes
HarperDB automatically creates two audit attributes used on each record if the table is created without a schema.
__createdtime__: The time the record was created in Unix Epoch with milliseconds format.__updatedtime__: The time the record was updated in Unix Epoch with milliseconds format.
Dynamic Schema Example
To better understand the behavior let’s take a look at an example. This example utilizes HarperDB API operations.
Create a Database
{
"operation": "create_database",
"schema": "dev"
}
Create a Table
Notice the schema name, table name, and primary key name are the only required parameters.
{
"operation": "create_table",
"database": "dev",
"table": "dog",
"primary_key": "id"
}
At this point the table does not have structure beyond what we provided, so the table looks like this:
dev.dog
![]()
Insert Record
To define attributes we do not need to do anything beyond sending them in with an insert operation.
{
"operation": "insert",
"database": "dev",
"table": "dog",
"records": [
{"id": 1, "dog_name": "Penny", "owner_name": "Kyle"}
]
}
With a single record inserted and new attributes defined, our table now looks like this:
dev.dog

Indexes have been automatically created for dog_name and owner_name attributes.
Insert Additional Record
If we continue inserting records with the same data schema no schema updates are required. One record will omit the hash attribute from the insert to demonstrate GUID generation.
{
"operation": "insert",
"database": "dev",
"table": "dog",
"records": [
{"id": 2, "dog_name": "Monk", "owner_name": "Aron"},
{"dog_name": "Harper","owner_name": "Stephen"}
]
}
In this case, there is no change to the schema. Our table now looks like this:
dev.dog
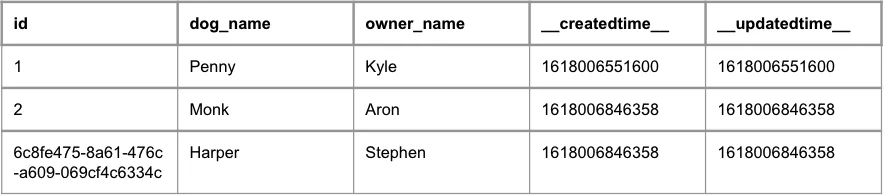
Update Existing Record
In this case, we will update a record with a new attribute not previously defined on the table.
{
"operation": "update",
"database": "dev",
"table": "dog",
"records": [
{"id": 2, "weight_lbs": 35}
]
}
Now we have a new attribute called weight_lbs. Our table now looks like this:
dev.dog
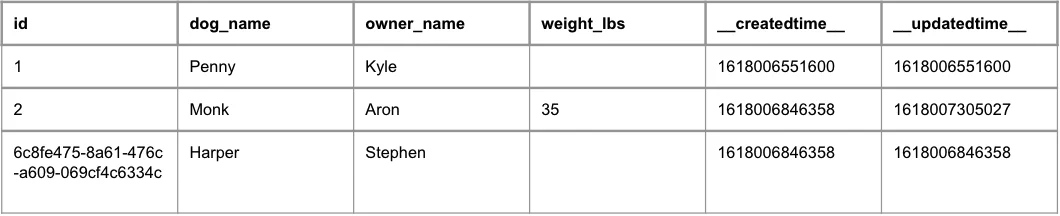
Query Table with SQL
Now if we query for all records where weight_lbs is null we expect to get back two records.
{
"operation": "sql",
"sql": "SELECT * FROM dev.dog WHERE weight_lbs IS NULL"
}
This results in the expected two records being returned.
